

Good references:
Sklearn GridSearchCV
Python机器学习笔记:Grid SearchCV(网格搜索)
GBDT、XGBoost、LightGBM 的使用及参数调优
How to Develop Your First XGBoost Model in Python with scikit-learn
Using XGBoost with Scikit-learn
Ensemble Methods: Tuning a XGBoost model with Scikit-Learn
In this demo, we will try to tune hyperparameters for XGBoost model sequentially using grid search rather than tune all hyperparameters at once.
Note:
Use model = xgb.XGBRegressor(**other_params) rather than model = xgb.XGBRegressor(other_params)!
Every time a parameter is tuned, the parameter corresponding to other_params must be updated to the optimal value!
Load data
#%reset
import numpy as np
import pickle
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
import xgboost as xgb
#import graphviz
fin = 'training_data/merged_data.pkl'
with open(fin, 'rb') as fp:
[xtr, xts, ytr, yts] = pickle.load(fp)
#Important: split training and validation data from original training data!
xtr, xval, ytr, yval = train_test_split(xtr, ytr, test_size=0.20, random_state=42, shuffle=True)
Defualt model traning and testing
xgb_model = xgb.XGBClassifier(objective="multi:softprob", random_state=42, eval_metric="auc", subsample=0.8)
xgb_model.fit(xtr, ytr, verbose=10)
y_pred = xgb_model.predict(xval)
print(xgb_model)
XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, eval_metric='auc',
gamma=0, gpu_id=-1, importance_type='gain',
interaction_constraints='', learning_rate=0.300000012,
max_delta_step=0, max_depth=6, min_child_weight=1, missing=nan,
monotone_constraints='()', n_estimators=100, n_jobs=0,
num_parallel_tree=1, objective='multi:softprob', random_state=42,
reg_alpha=0, reg_lambda=1, scale_pos_weight=None, subsample=0.8,
tree_method='exact', validate_parameters=1, verbosity=None)
#accuracy
accuracy = accuracy_score(yval, y_pred)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
Accuracy: 89.45%
Find an optimize model
Gridsearch function
from sklearn.model_selection import GridSearchCV
import sklearn.model_selection
X = np.vstack((xtr,xval))
y = np.hstack((ytr,yval))
ntr = len(ytr)
nts = len(yval)
test_fold = np.hstack((-1*np.ones(ntr), np.zeros(nts)))
ps = sklearn.model_selection.PredefinedSplit(test_fold)
#hyper-parameters
Niter_test=[100, 150, 200, 400]
max_depth_test = [3,6,10,15]
lr_test = [0.01, 0.1, 0.2, 0.4]
gam_test = [0., 0.1, 0.2, 0.3]
reg_lambda_test = [1e-3, 1e-2, 0.1, 1, 10, 100] #L2-norm
def gridsearch_cv(model, param_grid, X, y, ps, njobs):
clf = GridSearchCV(estimator=model, param_grid=param_grid, n_jobs=njobs, cv=ps, verbose=10)
print(clf)
clf.fit(X, y)
#print('CV Results: ', clf.cv_results_)
#print('Best Params: ', clf.best_params_)
#print('Best Score: ', clf.best_score_)
return clf
Optimize n_estimators
n_estimators is the optimal number of iterations or the number of weak learners.
other_params = {'objective': 'multi:softprob', 'random_state': 42, 'eval_metric': 'auc', 'subsample': 0.8}
model = xgb.XGBClassifier(**other_params)
#print(model)
#model = xgb.XGBClassifier(objective='multi:softprob', eval_metric="auc", random_state=42, subsample=0.8)
cv_params = {'n_estimators': Niter_test}
njobs = 4
clf = gridsearch_cv(model, cv_params, X, y, ps, njobs)
print(clf.cv_results_)
GridSearchCV(cv=PredefinedSplit(test_fold=array([-1, -1, ..., 0, 0])),
estimator=XGBClassifier(base_score=None, booster=None,
colsample_bylevel=None,
colsample_bynode=None,
colsample_bytree=None, eval_metric='auc',
gamma=None, gpu_id=None,
importance_type='gain',
interaction_constraints=None,
learning_rate=None, max_delta_step=None,
max_depth=None, min_child_weight=None,
missing=nan, monotone_constraints=None,
n_estimators=100, n_jobs=None,
num_parallel_tree=None,
objective='multi:softprob',
random_state=42, reg_alpha=None,
reg_lambda=None, scale_pos_weight=None,
subsample=0.8, tree_method=None,
validate_parameters=None, verbosity=None),
n_jobs=4, param_grid={'n_estimators': [100, 150, 200, 400]},
verbose=10)
Fitting 1 folds for each of 4 candidates, totalling 4 fits
[Parallel(n_jobs=4)]: Using backend LokyBackend with 4 concurrent workers.
[Parallel(n_jobs=4)]: Done 1 tasks | elapsed: 3.7min
[Parallel(n_jobs=4)]: Done 2 out of 4 | elapsed: 5.1min remaining: 5.1min
[Parallel(n_jobs=4)]: Done 4 out of 4 | elapsed: 9.1min remaining: 0.0s
[Parallel(n_jobs=4)]: Done 4 out of 4 | elapsed: 9.1min finished
CV Results: {'mean_fit_time': array([219.33839226, 299.2481606 , 362.04324269, 536.5468092 ]), 'std_fit_time': array([0., 0., 0., 0.]), 'mean_score_time': array([1.55304623, 2.2140727 , 3.15582633, 5.26072145]), 'std_score_time': array([0., 0., 0., 0.]), 'param_n_estimators': masked_array(data=[100, 150, 200, 400],
mask=[False, False, False, False],
fill_value='?',
dtype=object), 'params': [{'n_estimators': 100}, {'n_estimators': 150}, {'n_estimators': 200}, {'n_estimators': 400}], 'split0_test_score': array([0.89447761, 0.89544776, 0.89671642, 0.89746269]), 'mean_test_score': array([0.89447761, 0.89544776, 0.89671642, 0.89746269]), 'std_test_score': array([0., 0., 0., 0.]), 'rank_test_score': array([4, 3, 2, 1])}
Best Params: {'n_estimators': 400}
Best Score: 0.8974626865671642
From the results below, we can see that there are the same score for model with n_estimators=200 and 400. Thus, we take the best n_estimators as 200.
Optimize max_depth
max_depth is the max depth of a tree. Increasing this value will make the model more complex and more likely to overfit.
other_params = {'objective': 'multi:softprob', 'random_state': 42, 'eval_metric': 'auc', 'subsample': 0.8,
'n_estimators':200}
model = xgb.XGBClassifier(**other_params)
#print(model)
cv_params = {'max_depth': max_depth_test}
njobs = 4
clf = gridsearch_cv(model, cv_params, X, y, ps, njobs)
print(clf.cv_results_)
GridSearchCV(cv=PredefinedSplit(test_fold=array([-1, -1, ..., 0, 0])),
estimator=XGBClassifier(base_score=None, booster=None,
colsample_bylevel=None,
colsample_bynode=None,
colsample_bytree=None, eval_metric='auc',
gamma=None, gpu_id=None,
importance_type='gain',
interaction_constraints=None,
learning_rate=None, max_delta_step=None,
max_depth=None, min_child_weight=None,
missing=nan, monotone_constraints=None,
n_estimators=200, n_jobs=None,
num_parallel_tree=None,
objective='multi:softprob',
random_state=42, reg_alpha=None,
reg_lambda=None, scale_pos_weight=None,
subsample=0.8, tree_method=None,
validate_parameters=None, verbosity=None),
n_jobs=4, param_grid={'max_depth': [3, 6, 10, 15]}, verbose=10)
Fitting 1 folds for each of 4 candidates, totalling 4 fits
[Parallel(n_jobs=4)]: Using backend LokyBackend with 4 concurrent workers.
[Parallel(n_jobs=4)]: Done 1 tasks | elapsed: 4.3min
[Parallel(n_jobs=4)]: Done 2 out of 4 | elapsed: 6.3min remaining: 6.3min
[Parallel(n_jobs=4)]: Done 4 out of 4 | elapsed: 6.9min remaining: 0.0s
[Parallel(n_jobs=4)]: Done 4 out of 4 | elapsed: 6.9min finished
{'mean_fit_time': array([250.310534 , 374.99056125, 404.42518497, 406.44820809]), 'std_fit_time': array([0., 0., 0., 0.]), 'mean_score_time': array([2.06299019, 3.03603101, 3.56867194, 2.97454596]), 'std_score_time': array([0., 0., 0., 0.]), 'param_max_depth': masked_array(data=[3, 6, 10, 15],
mask=[False, False, False, False],
fill_value='?',
dtype=object), 'params': [{'max_depth': 3}, {'max_depth': 6}, {'max_depth': 10}, {'max_depth': 15}], 'split0_test_score': array([0.89626866, 0.89671642, 0.89880597, 0.89746269]), 'mean_test_score': array([0.89626866, 0.89671642, 0.89880597, 0.89746269]), 'std_test_score': array([0., 0., 0., 0.]), 'rank_test_score': array([4, 3, 1, 2])}
print('Best Params: ', clf.best_params_)
print('Best Score: %0.4g' %clf.best_score_)
Best Params: {'max_depth': 10}
Best Score: 0.8988
From the results below, we can see that maximum depth 10 gives the best score 0.8988.
Optimize gamma and reg_lambda
Minimum loss reduction required to make a further partition on a leaf node of the tree. The larger gamma is, the more conservative the algorithm will be.
reg is a L2 regularization term on weights. Increasing this value will make model more conservative. Normalised to number of training examples.
other_params = {'objective': 'multi:softprob', 'random_state': 42, 'eval_metric': 'auc', 'subsample': 0.8,
'n_estimators':200, 'max_depth': 10}
model = xgb.XGBClassifier(**other_params)
#print(model)
cv_params = {'gamma': gam_test, 'reg_lambda': reg_lambda_test}
njobs = 4
clf = gridsearch_cv(model, cv_params, X, y, ps, njobs)
GridSearchCV(cv=PredefinedSplit(test_fold=array([-1, -1, ..., 0, 0])),
estimator=XGBClassifier(base_score=None, booster=None,
colsample_bylevel=None,
colsample_bynode=None,
colsample_bytree=None, eval_metric='auc',
gamma=None, gpu_id=None,
importance_type='gain',
interaction_constraints=None,
learning_rate=None, max_delta_step=None,
max_depth=10, min_child_weight=None,
missing=nan, monotone_constraints=None,
n_estimators=200, n_jobs=None,
num_parallel_tree=None,
objective='multi:softprob',
random_state=42, reg_alpha=None,
reg_lambda=None, scale_pos_weight=None,
subsample=0.8, tree_method=None,
validate_parameters=None, verbosity=None),
n_jobs=4,
param_grid={'gamma': [0.0, 0.1, 0.2, 0.3],
'reg_lambda': [0.001, 0.01, 0.1, 1, 10, 100]},
verbose=10)
Fitting 1 folds for each of 24 candidates, totalling 24 fits
[Parallel(n_jobs=4)]: Using backend LokyBackend with 4 concurrent workers.
[Parallel(n_jobs=4)]: Done 5 tasks | elapsed: 15.5min
[Parallel(n_jobs=4)]: Done 10 tasks | elapsed: 24.6min
[Parallel(n_jobs=4)]: Done 17 tasks | elapsed: 42.9min
[Parallel(n_jobs=4)]: Done 20 out of 24 | elapsed: 49.0min remaining: 9.8min
[Parallel(n_jobs=4)]: Done 24 out of 24 | elapsed: 58.2min finished
print(clf.cv_results_)
print('Best Params: ', clf.best_params_)
print('Best Score: %0.4g' %clf.best_score_)
{'mean_fit_time': array([404.28340697, 400.29925346, 401.53780079, 435.2927022 ,
585.22974706, 713.03687501, 515.37082434, 514.35972023,
488.64769959, 511.99894309, 586.02537799, 685.42307258,
528.94938993, 529.09306049, 532.39049315, 554.98072243,
617.56116581, 702.50300646, 559.10517311, 556.37984872,
559.82931995, 554.74631739, 589.34720969, 545.09472537]), 'std_fit_time': array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.]), 'mean_score_time': array([4.37557888, 4.66015029, 5.06264257, 4.09290457, 6.237679 ,
9.16920233, 3.06602764, 3.12065005, 2.74554229, 3.0090003 ,
5.09211946, 6.99369597, 2.73910427, 2.72157264, 2.6582725 ,
2.91256833, 4.05202961, 5.6127677 , 2.80606484, 2.80110574,
2.6645627 , 2.47576356, 2.82322264, 3.42771006]), 'std_score_time': array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.]), 'param_gamma': masked_array(data=[0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.1, 0.1, 0.1, 0.1, 0.1,
0.1, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.3, 0.3, 0.3, 0.3,
0.3, 0.3],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False],
fill_value='?',
dtype=object), 'param_reg_lambda': masked_array(data=[0.001, 0.01, 0.1, 1, 10, 100, 0.001, 0.01, 0.1, 1, 10,
100, 0.001, 0.01, 0.1, 1, 10, 100, 0.001, 0.01, 0.1, 1,
10, 100],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False],
fill_value='?',
dtype=object), 'params': [{'gamma': 0.0, 'reg_lambda': 0.001}, {'gamma': 0.0, 'reg_lambda': 0.01}, {'gamma': 0.0, 'reg_lambda': 0.1}, {'gamma': 0.0, 'reg_lambda': 1}, {'gamma': 0.0, 'reg_lambda': 10}, {'gamma': 0.0, 'reg_lambda': 100}, {'gamma': 0.1, 'reg_lambda': 0.001}, {'gamma': 0.1, 'reg_lambda': 0.01}, {'gamma': 0.1, 'reg_lambda': 0.1}, {'gamma': 0.1, 'reg_lambda': 1}, {'gamma': 0.1, 'reg_lambda': 10}, {'gamma': 0.1, 'reg_lambda': 100}, {'gamma': 0.2, 'reg_lambda': 0.001}, {'gamma': 0.2, 'reg_lambda': 0.01}, {'gamma': 0.2, 'reg_lambda': 0.1}, {'gamma': 0.2, 'reg_lambda': 1}, {'gamma': 0.2, 'reg_lambda': 10}, {'gamma': 0.2, 'reg_lambda': 100}, {'gamma': 0.3, 'reg_lambda': 0.001}, {'gamma': 0.3, 'reg_lambda': 0.01}, {'gamma': 0.3, 'reg_lambda': 0.1}, {'gamma': 0.3, 'reg_lambda': 1}, {'gamma': 0.3, 'reg_lambda': 10}, {'gamma': 0.3, 'reg_lambda': 100}], 'split0_test_score': array([0.89507463, 0.8958209 , 0.89537313, 0.89880597, 0.89955224,
0.89843284, 0.8938806 , 0.89261194, 0.89410448, 0.89679104,
0.89902985, 0.89783582, 0.89328358, 0.89134328, 0.89365672,
0.89507463, 0.89776119, 0.89671642, 0.89283582, 0.89358209,
0.89097015, 0.89537313, 0.89723881, 0.8961194 ]), 'mean_test_score': array([0.89507463, 0.8958209 , 0.89537313, 0.89880597, 0.89955224,
0.89843284, 0.8938806 , 0.89261194, 0.89410448, 0.89679104,
0.89902985, 0.89783582, 0.89328358, 0.89134328, 0.89365672,
0.89507463, 0.89776119, 0.89671642, 0.89283582, 0.89358209,
0.89097015, 0.89537313, 0.89723881, 0.8961194 ]), 'std_test_score': array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.]), 'rank_test_score': array([14, 11, 12, 3, 1, 4, 17, 22, 16, 8, 2, 5, 20, 23, 18, 14, 6,
9, 21, 19, 24, 12, 7, 10])}
Best Params: {'gamma': 0.0, 'reg_lambda': 10}
Best Score: 0.8996
From the results below, we can see that gamma=0 and L2 norm paramter reg_lambda=10 give the best score 0.8996.
Optimaize learning rate
learning rate is the step size shrinkage used in update to prevents overfitting. After each boosting step, we can directly get the weights of new features, and eta shrinks the feature weights to make the boosting process more conservative.
other_params = {'objective': 'multi:softprob', 'random_state': 42, 'eval_metric': 'auc', 'subsample': 0.8,
'n_estimators':200, 'max_depth': 10, 'gamma': 0, 'reg_lambda': 10}
model = xgb.XGBClassifier(**other_params)
print(model)
cv_params = {'learning_rate': lr_test}
njobs = 4
clf = gridsearch_cv(model, cv_params, X, y, ps, njobs)
XGBClassifier(base_score=None, booster=None, colsample_bylevel=None,
colsample_bynode=None, colsample_bytree=None, eval_metric='auc',
gamma=0, gpu_id=None, importance_type='gain',
interaction_constraints=None, learning_rate=None,
max_delta_step=None, max_depth=10, min_child_weight=None,
missing=nan, monotone_constraints=None, n_estimators=200,
n_jobs=None, num_parallel_tree=None, objective='multi:softprob',
random_state=42, reg_alpha=None, reg_lambda=10,
scale_pos_weight=None, subsample=0.8, tree_method=None,
validate_parameters=None, verbosity=None)
GridSearchCV(cv=PredefinedSplit(test_fold=array([-1, -1, ..., 0, 0])),
estimator=XGBClassifier(base_score=None, booster=None,
colsample_bylevel=None,
colsample_bynode=None,
colsample_bytree=None, eval_metric='auc',
gamma=0, gpu_id=None,
importance_type='gain',
interaction_constraints=None,
learning_rate=None, max_delta_step=None,
max_depth=10, min_child_weight=None,
missing=nan, monotone_constraints=None,
n_estimators=200, n_jobs=None,
num_parallel_tree=None,
objective='multi:softprob',
random_state=42, reg_alpha=None,
reg_lambda=10, scale_pos_weight=None,
subsample=0.8, tree_method=None,
validate_parameters=None, verbosity=None),
n_jobs=4, param_grid={'learning_rate': [0.01, 0.1, 0.2, 0.4]},
verbose=10)
Fitting 1 folds for each of 4 candidates, totalling 4 fits
[Parallel(n_jobs=4)]: Using backend LokyBackend with 4 concurrent workers.
[Parallel(n_jobs=4)]: Done 1 tasks | elapsed: 9.3min
[Parallel(n_jobs=4)]: Done 2 out of 4 | elapsed: 10.6min remaining: 10.6min
[Parallel(n_jobs=4)]: Done 4 out of 4 | elapsed: 11.4min remaining: 0.0s
[Parallel(n_jobs=4)]: Done 4 out of 4 | elapsed: 11.4min finished
print(clf.cv_results_)
print('Best Params: ', clf.best_params_)
print('Best Score: %0.4g' %clf.best_score_)
{'mean_fit_time': array([664.7326026 , 671.92150831, 622.16494417, 548.31287384]), 'std_fit_time': array([0., 0., 0., 0.]), 'mean_score_time': array([5.62669063, 5.99123359, 7.20477128, 5.30254006]), 'std_score_time': array([0., 0., 0., 0.]), 'param_learning_rate': masked_array(data=[0.01, 0.1, 0.2, 0.4],
mask=[False, False, False, False],
fill_value='?',
dtype=object), 'params': [{'learning_rate': 0.01}, {'learning_rate': 0.1}, {'learning_rate': 0.2}, {'learning_rate': 0.4}], 'split0_test_score': array([0.8819403 , 0.89940299, 0.90067164, 0.89955224]), 'mean_test_score': array([0.8819403 , 0.89940299, 0.90067164, 0.89955224]), 'std_test_score': array([0., 0., 0., 0.]), 'rank_test_score': array([4, 3, 1, 2])}
Best Params: {'learning_rate': 0.2}
Best Score: 0.9007
From the results below, we can see that learning_rate=0.2 gives the best score 0.901.
In conclusion, the setting of hyperparameters {n_estimators=200, max_depth=10, gamma=0, reg_lambda=10, learning_rate=0.2} will produce the best XGBoost model.
Using the optimal settings and test data to predict
xgb_model = xgb.XGBClassifier(objective="multi:softprob", random_state=42, eval_metric="auc", subsample=0.8,
n_estimators=200, max_depth=10, gamma=0, reg_lambda=10, learning_rate = 0.2)
xgb_model.fit(xtr, ytr, verbose=10)
print(xgb_model)
y_pred = xgb_model.predict(xts) #test data
XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, eval_metric='auc',
gamma=0, gpu_id=-1, importance_type='gain',
interaction_constraints='', learning_rate=0.2, max_delta_step=0,
max_depth=10, min_child_weight=1, missing=nan,
monotone_constraints='()', n_estimators=200, n_jobs=0,
num_parallel_tree=1, objective='multi:softprob', random_state=42,
reg_alpha=0, reg_lambda=10, scale_pos_weight=None, subsample=0.8,
tree_method='exact', validate_parameters=1, verbosity=None)
#accuracy
accuracy = accuracy_score(yts, y_pred)
print("Accuracy: %.2f%%" % (accuracy * 100.0))
#confusion matrix
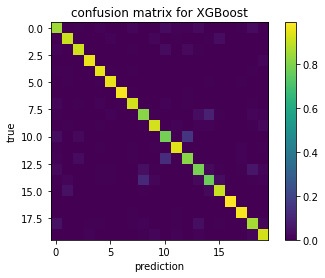
CM = confusion_matrix(yts, y_pred)
# Normalize the confusion matrix
CMsum = np.sum(CM,1)
CM = CM / CMsum[np.newaxis,:]
# Plot the confusion matrix
plt.imshow(CM, interpolation='none')
plt.colorbar()
plt.title('confusion matrix for XGBoost')
plt.xlabel('prediction')
plt.ylabel('true')
#importance plot
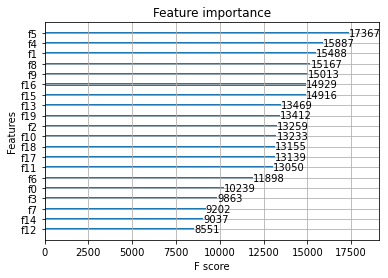
xgb.plot_importance(xgb_model)
#draw target tree: converts the target tree to a graphviz instance
#xgb.to_graphviz(xgb_model)
Accuracy: 89.82%
Note that this is my lab assignment for Machine learning course!
Last update: 12/04/2020