

Neural networks involve millions of parameters that are prohibitively difficult to train from scratch.A powerful technique called transfer learning, where we start with a large pre-trained network and then re-train only the final layers to adapt it to a new task. The method is also called fine-tuning and can produce excellent results on very small datasets with very little computational time.
This is based partially on this
excellent blog, althought the details there are for Keras.
Goal:
- Build a custom image dataset
- Fine tune the final layers of an existing deep neural network for a new classification task.
Create a Dataset
We will train a network to discriminate between two classes: cars and bicycles. The first task is to build a dataset.
TODO: Create training and test directories with:
- 1000 training images of cars
- 1000 training images of bicylces
- 300 test images of cars
- 300 test images of bicycles
- The images don’t need to be the same size.
The images should be organized in the following directory structure:
./train
/car
car_0000.jpg
car_0001.jpg
...
car_0999.jpg
/bicycle
bicycle_0000.jpg
bicycle_0001.jpg
...
bicycle_0999.jpg
./test
/car
car_0000.jpg
car_0001.jpg
...
car_0299.jpg
/bicycle
bicycle_0000.jpg
bicycle_0001.jpg
...
bicycle_0299.jpg
Now we’ll select the image dimensions for our neural network. They need not be the same as those of the downloaded images, or even the 224x224 size that the network was optimized for, but they should be small enough to work on your machine without taking forever. If you have a CPU machine, a good choice is 64 x 64. But if you have a GPU image, then you can use a larger image size, like 150 x 150.
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import skimage.io
import skimage.transform
import urllib
import requests
from io import BytesIO
import flickrapi
import os
api_key = '******'
api_secret = '******'
flickr = flickrapi.FlickrAPI(api_key, api_secret)
keyword = 'car'
ph_car = flickr.walk(text=keyword, tag_mode='all', tags=keyword,extras='url_c',\
sort='relevance',per_page=100)
keyword = 'bicycle'
ph_bicycle = flickr.walk(text=keyword, tag_mode='all', tags=keyword,extras='url_c',\
sort='relevance',per_page=100)
# declare directory names
train_dir = 'train'
test_dir = 'test'
image_dir = ['car','bicycle']
# make a directories for the training and testing images
dir_path = []
for root_dir in [train_dir,test_dir]:
# check if data exists
if not os.path.isdir(root_dir):
os.mkdir(root_dir)
for data_dir in image_dir:
dir_path = root_dir + '/' + data_dir
if not os.path.isdir(dir_path):
os.mkdir(dir_path)
print("Making directory %s" % dir_path)
else:
print("Will store %s images in directory %s" %(root_dir,dir_path))
Will store train images in directory train/car
Will store train images in directory train/bicycle
Will store test images in directory test/car
Will store test images in directory test/bicycle
import warnings
from random import seed
from random import random
ntrain = 1000 # number of training images to download
ntest = 300 # number of testing images to download
nrow = 64 # image dimension 1
ncol = 64 # image dimension 2
def download_img(photos, image_dir):
keyword = image_dir
# download images, first train then test
seed(1) # make repeatable
itrain = 0 # initialize counter
itest = 0 # initialize counter
inum = -1
for photo in photos:
url=photo.get('url_c')
if not (url is None):
# Create a file from the URL
# This may only work in Python3
response = requests.get(url)
file = BytesIO(response.content)
# Read image from file
im = skimage.io.imread(file)
# Resize images
#im1 = skimage.transform.resize(im,(nrow,ncol),mode='constant')
# Convert to uint8, suppress the warning about the precision loss
with warnings.catch_warnings():
warnings.simplefilter("ignore")
#im2 = skimage.img_as_ubyte(im1)
im2 = skimage.img_as_ubyte(im)
# Set the directory randomly
#if (random()< ntrain/(ntrain+ntest)):
if (random()< (ntrain-itrain)/(ntrain-itrain + ntest-itest + 1e-15)):
if (itrain<ntrain):
dir_path = train_dir + '/' + image_dir
i = itrain
itrain = itrain + 1
elif (itest<ntest):
dir_path = test_dir + '/' + image_dir
i = itest
itest = itest + 1
else:
break
else:
if (itest<ntest):
dir_path = test_dir + '/' + image_dir
i = itest
itest = itest + 1
elif (itrain<ntrain):
dir_path = train_dir + '/' + image_dir
i = itrain
itrain = itrain + 1
else:
break
# Save the image
local_name = '{0:s}/{1:s}_{2:04d}.jpg'.format(dir_path,keyword,i)
skimage.io.imsave(local_name, im2)
inum += 1
if inum%100 == 0:
print(local_name)
#call function
download_img(ph_car, 'car')
download_img(ph_bicycle, 'bicycle')
train/car/car_0000.jpg
train/car/car_0075.jpg
train/car/car_0156.jpg
train/car/car_0225.jpg
test/car/car_0097.jpg
train/car/car_0377.jpg
train/car/car_0456.jpg
train/car/car_0534.jpg
train/car/car_0605.jpg
test/car/car_0220.jpg
train/car/car_0757.jpg
train/car/car_0845.jpg
train/car/car_0921.jpg
train/bicycle/bicycle_0000.jpg
train/bicycle/bicycle_0075.jpg
train/bicycle/bicycle_0156.jpg
train/bicycle/bicycle_0225.jpg
test/bicycle/bicycle_0097.jpg
train/bicycle/bicycle_0377.jpg
train/bicycle/bicycle_0456.jpg
train/bicycle/bicycle_0534.jpg
train/bicycle/bicycle_0605.jpg
test/bicycle/bicycle_0220.jpg
train/bicycle/bicycle_0757.jpg
train/bicycle/bicycle_0845.jpg
train/bicycle/bicycle_0921.jpg
Using the DataLoader with ImageFolder
We will now create an ImageFolder object. We will use a torchvision.transform to preprocess the data when training our network.
Randomly crop a section of between 0.5 and 1 of the original image size, and then resize it to nrow x ncol pixels.
Also, use the following normalization (the default for ImageNet):
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
import torch
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
# Create a transformation that converts to a tensor then and crops to a desired size (we'll do 64x64)
crop = transforms.RandomResizedCrop(64,scale=(0.5,1.0))
transform = transforms.Compose([crop, transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# Create a DataSet, using our transform and folder
train_ds = ImageFolder(root='train', transform=transform)
batch_size = 50
train_dl = DataLoader(train_ds, batch_size=batch_size, shuffle=True)
Now, create a test_dl object for the test data, using the same data transform as for the training.
# Create a DataSet, using our transform and folder
test_ds = ImageFolder(root='test', transform=transform)
batch_size = 50
test_dl = DataLoader(test_ds, batch_size=batch_size)
The following image display function will be useful later.
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
#### Code from https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html #####
def imshow(inp, title=None):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0)) # rearrange dimensions from (color,y,x) -> (y,x,color)
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean # undo the normalization
inp = np.clip(inp, 0, 1)
# Display image, without ticks
plt.imshow(inp)
plt.xticks([])
plt.yticks([])
if title is not None:
plt.title(title)
###########################################################################################
To see how the train_dl works, use the next(iter(train_dl)) method to get a minibatch of data X,y. Display the first 8 images in this mini-batch and label the image with its class label. You should see that bicycles have y=0 and cars have y=1.
x, y = next(iter(train_dl))
from torchvision.utils import make_grid
%matplotlib inline
imshow(make_grid(x[0:8,:,:,:]),y[0:8])

Loading a Pre-Trained Deep Network
Load a pre-trained VGG16 network. Rember to set pretrained=True in order to also load the pre-trained weights.
import torch
from torchvision.models import vgg16
# Load the VGG16 network
model = vgg16(pretrained=True)
print(str(model))
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
Now, freeze the parameters of the pretrained model. To do this, loop over the parameters in the model and set their requires_grad flag to False. This will stop PyTorch from calculating the gradient for those parameters and stop them from being updated by the optimizer.
# freeze layers
#print(model.features.parameters)
# ct = 0
# for child in model.children():
# ct += 1
# #print(ct)
# if ct <= 2:
# for param in child.parameters():
# param.requires_grad = False
# or
#for param1 in model.features.parameters():
# param1.requires_grad = False
# for param2 in model.avgpool.parameters():
# param2.requires_grad = False
#or simply
for param in model.features.parameters():
param.requires_grad = False
Remember, from the VGG16 demo, that the network has a features portion, with convolutional layers, and a classifier portion, with fully connected layers. We will keeping the features portion but replace the classifier portion. The idea is that the features portion, which was trained on all of ImageNet, will generate useful features for any image classification task, such as differentiating cars and bikes.
In order to replace the classifier portion, we first need to find the size of the input to the classifier portion of the network, so that we can build our own with the proper size. You can do this using
print(model.classifier[0])
#print(model.classifier)
Linear(in_features=25088, out_features=4096, bias=True)
Replace model.classifier with a neural network consisting of the following layers:
- Linear w/ 256 output channels
- ReLU
- Dropout w/ p = 0.5
- Linear w/ 1 output channel (indicating car vs bike)
- Sigmoid
This network can be constructed using 1 line via nn.Sequential.
import torch.nn as nn
num_classes = 1
# Replace the classifier part of the network
model.classifier = nn.Sequential(
nn.Linear(25088, 256),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(256, num_classes),
nn.Sigmoid(),
)
Now we will print a summary of the model.
Confirm that it includes a features portion and a classifier portion, each constructed by a Sequential() object.
The features portion should be the same as the VGG network, and the classifier portion should consist of the following sequence of Modules: Linear, Relu, Dropout, Linear, Sigmoid.
print(str(model))
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=256, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=256, out_features=1, bias=True)
(4): Sigmoid()
)
)
Train the Model
Select the correct loss function and an optimizer to train the model.
Remember that we are doing binary classification, so do not copy-and-paste code from non-binary classification (e.g., the classifier demo) and expect it to work!
import torch.optim as optim
lrate = 1e-3
# initiate Adam optimizer
opt = optim.Adam(model.parameters(), lr=lrate)
criterion = nn.BCELoss()
Now, run the training. If you are using a CPU on a regular laptop, each epoch should take about 1-4 minutes, so you should be able to finish 5 epochs or so within 5-20 minutes. On a reasonable GPU, even with 150 x 150 images, it should take about 10 seconds per epoch. If you use (nrow,ncol) = (64,64) images, you should get about 90-95% accuracy after 5 epochs.
epochs = 5
a_tr_loss = np.zeros([epochs])
a_tr_accuracy = np.zeros([epochs])
a_ts_loss = np.zeros([epochs])
a_ts_accuracy = np.zeros([epochs])
for epoch in range(epochs):
correct = 0 # initialize error counter
total = 0 # initialize total counter
model.train() # put model in training mode
batch_loss_tr = []
# iterate over training set
for train_iter, data in enumerate(train_dl):
x_batch,y_batch = data
out = model(x_batch)
#y_batch = y_batch.to(dtype=torch.float)
y_batch = y_batch.reshape(-1,1)
# Compute Loss
loss = criterion(out,y_batch.type(torch.float))
batch_loss_tr.append(loss.item())
# Zero gradients
opt.zero_grad()
# Compute gradients using back propagation
loss.backward()
# Take an optimization 'step'
opt.step()
# Compute Accuracy
#print(out) #the size of out = batch size!
predict = out
predict[predict>=0.5] = 1
predict[predict<0.5] = 0
predict = predict.to(dtype=torch.long)
total += y_batch.size(0)
correct += (predict == y_batch).sum().item()
a_tr_loss[epoch] = np.mean(batch_loss_tr) # Compute average loss over epoch
a_tr_accuracy[epoch] = 100*correct/total
correct = 0
total = 0
batch_loss_ts = []
model.eval() # put model in evaluation mode
with torch.no_grad():
for data in test_dl:
images, labels = data
labels = labels.reshape(-1,1)
outputs = model(images)
batch_loss_ts.append(criterion(outputs,labels.type(torch.float)).item())
predicted = outputs
predicted[predicted>=0.5] = 1
predicted[predicted<0.5] = 0
predicted = predicted.to(dtype=torch.long)
total += labels.size(0)
correct += (predicted == labels).sum().item()
a_ts_loss[epoch] = np.mean(batch_loss_ts)
a_ts_accuracy[epoch] = 100*correct/total
# Print details every print_mod epoch
print('Epoch: {0:2d} Train Loss: {1:.3f} '.format(epoch+1, a_tr_loss[epoch])
+'Train Accuracy: {0:.2f} Test Loss: {1:.3f} '.format(a_tr_accuracy[epoch], a_ts_loss[epoch])
+'Test Accuracy: {0:.2f}'.format(a_ts_accuracy[epoch]))
print('Done!')
# Save
PATH = 'saved_basic_model.pt'
torch.save(model.state_dict(), PATH)
Epoch: 1 Train Loss: 0.499 Train Accuracy: 95.05 Test Loss: 0.241 Test Accuracy: 96.33
Epoch: 2 Train Loss: 0.316 Train Accuracy: 97.60 Test Loss: 0.210 Test Accuracy: 97.83
Epoch: 3 Train Loss: 0.252 Train Accuracy: 97.60 Test Loss: 0.226 Test Accuracy: 97.67
Epoch: 4 Train Loss: 0.120 Train Accuracy: 98.15 Test Loss: 0.096 Test Accuracy: 98.00
Epoch: 5 Train Loss: 0.058 Train Accuracy: 98.30 Test Loss: 0.137 Test Accuracy: 97.67
Done!
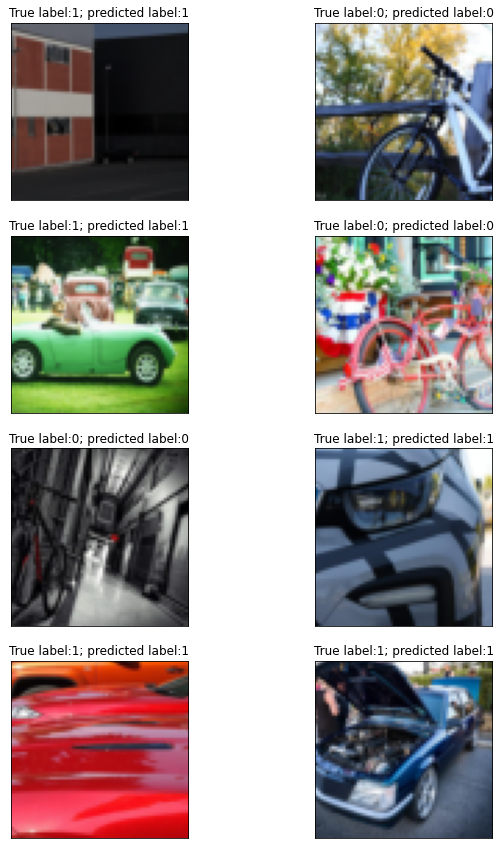
Finally, show some example test images with their predicted and actual labels in the title.
n_show = 8
eg_dl = DataLoader(test_ds, batch_size=1, shuffle=True)
fig = plt.figure(figsize=(10,15))
with torch.no_grad():
for i, data in enumerate(eg_dl):
if i >= n_show:
break
images, labels = data
out = model(images)
predicted = out
predicted[predicted>=0.5] = 1
predicted[predicted<0.5] = 0
predicted = predicted.to(dtype=torch.long)
plt.subplot(4, 2, i+1)
imshow(images[0])
plt.title('True label:'+str(int(labels[0]))+'; predicted label:'+str(int(predicted)))
Tips:
Reconstruct the code:
The following part of code
# iterate over training set
for train_iter, data in enumerate(train_dl):
x_batch,y_batch = data
out = model(x_batch)
#y_batch = y_batch.to(dtype=torch.float)
y_batch = y_batch.reshape(-1,1)
# Compute Loss
loss = criterion(out,y_batch.type(torch.float))
batch_loss_tr.append(loss.item())
# Zero gradients
opt.zero_grad()
# Compute gradients using back propagation
loss.backward()
# Take an optimization 'step'
opt.step()
# Compute Accuracy
#print(out) #the size of out = batch size!
predict = out
predict[predict>=0.5] = 1
predict[predict<0.5] = 0
predict = predict.to(dtype=torch.long)
total += y_batch.size(0)
correct += (predict == y_batch).sum().item()
can be replaced as follows:
# iterate over training set
for train_iter, data in enumerate(train_dl):
x_batch,y_batch = data
y_batch = y_batch.view(-1,1)
out = model(x_batch)
# Compute Loss
loss = criterion(out,y_batch.type(torch.float))
batch_loss.append(loss.item())
# Zero gradients
opt.zero_grad()
# Compute gradients using back propagation
loss.backward()
# Take an optimization 'step'
opt.step()
#
predicted = out.clamp(0,1).round().type(torch.long)
total += y_batch.size(0)
correct += (predicted == y_batch).sum().item()
- TENSOR.item()
Returns the value of this tensor as a standard Python number. Use torch.Tensor.item() to get a Python number from a tensor containing a single value:>>> x = torch.tensor([[1]]) >>> x tensor([[ 1]]) >>> x.item() 1 >>> x = torch.tensor(2.5) >>> x tensor(2.5000) >>> x.item() 2.5 - TORCH.ROUND
Returns a new tensor with each of the elements of input rounded to the closest integer. (四舍五入)
How to understand y_batch = y_batch.view(-1,1)?
- TENSOR.VIEWS
PyTorch allows a tensor to be a View of an existing tensor. View tensor shares the same underlying data with its base tensor. Supporting View avoids explicit data copy, thus allows us to do fast and memory efficient reshaping, slicing and element-wise operations. This can be used to replace reshape!
e.g.t = torch.rand(3, 2) print(t) b1 = t.reshape(-1, 1) print(b1) #or b2 = t.view(-1, 1) print(b2) b1 = b1.round().type(torch.long) print(b1)tensor([[0.2320, 0.4731], [0.8958, 0.5523], [0.3532, 0.6521]]) tensor([[0.2320], [0.4731], [0.8958], [0.5523], [0.3532], [0.6521]]) tensor([[0.2320], [0.4731], [0.8958], [0.5523], [0.3532], [0.6521]]) tensor([[0], [0], [1], [1], [0], [1]])
How to understand predicted = out.clamp(0,1).round().type(torch.long)?
- TORCH.CLAMP
torch.clamp(input, min, max, *, out=None) → Tensor

This line of code means that convert out to either 0 or 1 and transfer its type to long int.
A good blog reference:
pytorch一步一步在VGG16上训练自己的数据集
Note that this is my lab assignment for Machine learning course!
Last update: 11/18/2020